 Jun 16, 2022
Jun 16, 2022
Improving Iterable data flows with the help of Reverse ETL (Census)
End-to-end data pipelines
Why do we aim for healthy data flows?
Healthy data flows are a result of robust and transparent data pipelines. Data should follow a pre-designed path and end in an expected format in the destinations. The quality of the data path implementation can be measured by these dimensions of a healthy data flow:
- Data completeness - the data is not weirdly disappearing somewhere in the path and we get the expected number of data points in the destination.
- Data correctness - the values in the data points are the correct ones that we expect to see. The transformations during the path have worked as expected.
- Data freshness - the data is arriving at the expected time at the intermediate checkpoints and at the destination. All these dimensions are essential to building data trustworthiness across the organization, and also to delivering the best experience for our Issuu customers.
The previous state of Iterable data flows
Iterable is a marketing platform for creating, optimizing, and measuring the interaction we have with our customers. To deliver the best interaction, we need the data on time, correctly, and completely. Unfortunately, we had cases where we were failing to deliver what we wanted due to the obscurity of the previous state of the Iterable data flows. Don’t get me wrong, there was nothing wrong with any specific implementation, the problem was the full overall interaction of all components, which were failing to live in harmony. Iterable has had different sources of data input, some through our live event-handler, some manual imports, some on-demand updates, and so on. The data has been sent to Iterable without following a predefined standard, and due to the flexibility that Iterable offers, things were getting out of control.
We are using Fivetran to bring the data to our Data Lake. Fivetran brings a table called user_history, which keeps the history of user attributes. However, this table has a huge problem: it does not mark if a user was deleted on the source! We repeatedly delete users from Iterable when they opt-out of our promotions and campaigns and wish to not be contacted.
Finally, we had limited attributes on each data point on Iterable (fields missing for specific users) and our Marketing colleagues needed better support for enriching data. That is when we started considering Reverse ETL and especially Census.
Census as our Reverse ETL tool
Reverse ETL is an ETL process where the source and destination are swapped, so we read from the Data Lake/Datawarehouse/Datamart and send data to a source, like Iterable. Reverse ETL is powerful, given that you basically have the possibility to clean, merge, enrich data, and send something beautiful back to the source.
We came across Census in July 2021 with our first use case of sending data to Salesforce. We subscribed to their services very soon after the trial. Basically, they have a great UI where you write your SQL and send it to a huge variety of destinations. That’s easy! Then, you can schedule your sync, monitor it, set alerts, check what succeeded and failed, etc. Besides, their customer support is great and we have received full support for our use cases. Now, I would like to note that a Reverse ETL tool can be simply a tool to send data fast, but Census is more than that. Recently, they brought a new feature for storing logs in the Data warehouse and that gave us visibility for our full data flow.
How Census logs aided us to troubleshoot Iterable data flows?
We started by putting Census at the end of our data pipeline, as in the Figure below. Process 1 is managed by Fivetran and brings the data to our Data Lake environment, where other sources store their data as well. Process 2 is fully implemented in dbt by our Data Engineering team. Finally, we perform Reverse ETL with Census in process 3 to send data back to Iterable. Process 4 is managed by Census and writes the logs of the Reverse ETL job back to the Datawarehouse. Read more about this feature here.
These are the iterations we performed to troubleshoot and improve the data in Iterable:
Iteration 1: The logs of Census showed weird behaviors. First, 3.5 million users were not found on Iterable, while our user_history table of Fivetran believed they were there (remember, no delete label). Additionally, we could manually find some examples of users on Iterable missing from user_history. This led us to believe that our current schema of Iterable in our Data Lake had severe discrepancies. After discussing this internally, we decided that we should re-sync historically Process 1 (with Fivetran) to be able to have a fresh start.
Iteration 2: The logs of Census had around 700,000 rejections with errors like “User with this id is not found”. So we implemented a sync that matches on the email and updates the user_id in order to fix this issue.
Iteration 3: The logs of Census failed for 7760 records that were found to have the same user id but different emails. This meant that we had old emails of users that needed to be taken out of Iterable. We performed some joins in our Data lake to find the right email, and for every other record with other emails that is not the current version, we deleted them from Iterable.
Iteration 4: Our main pipeline has a full dependency on Fivetran data. This means that if Fivetran has slowed down, new users ids will arrive late. Consequently, the current Reverse ETL sync will experience delays. However, it is of high importance for us that users that join our platform are welcomed through Iterable and guided through a smooth journey. Thus, we decided on having another sync that originates from our internal Issuu data, independent from Fivetran sync of Iterable. We have a fast lane sync (Process 5) that reads directly from Issuu data and updates the records accordingly. This is a batch process and follows our streaming process for creating the users on Iterable. Therefore, through the Census rejections, we can see if the streaming process has created all the records it should, given a time window. Additionally, we can run a batch process to insert what is missing and improve the data completeness of the streaming process.
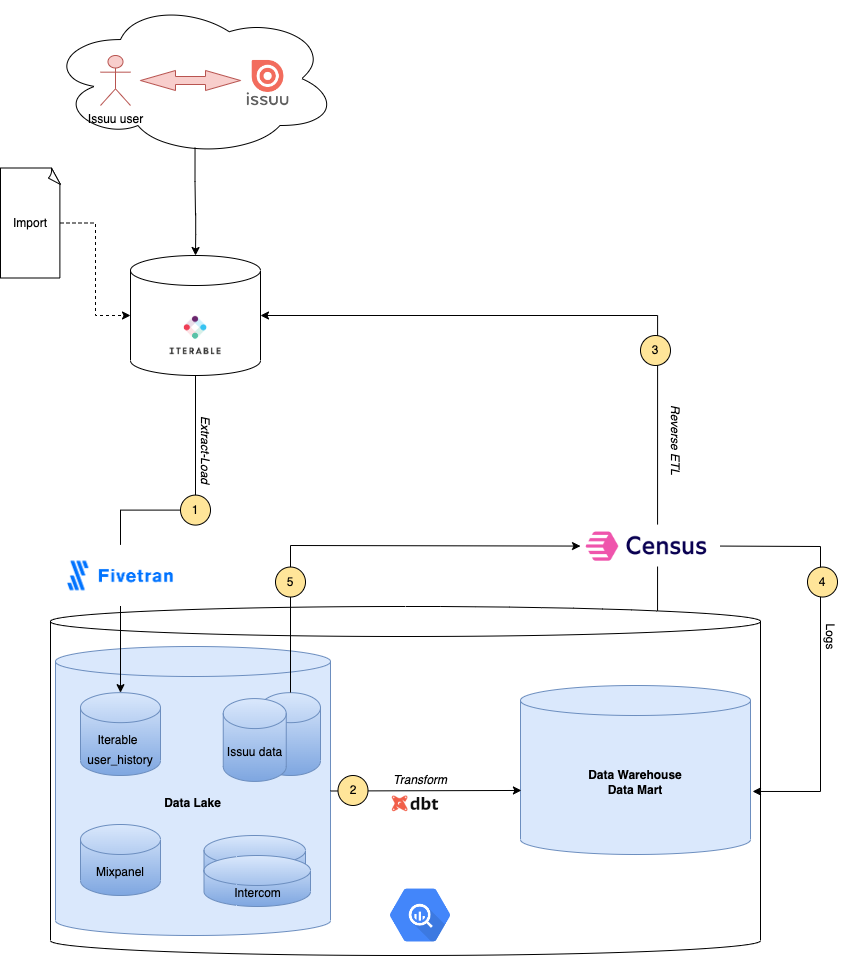
Designing a healthy Iterable data flow
A stack of tools is very challenging to debug when they are all put together and have different transformations. However, these were our takeaways regarding this work:
- Use dbt for transformations. dbt provides data lineage and full transparency of dbt models, so troubleshooting process 2 is fully feasible. Additionally, dbt has several packages for monitoring data and ensuring data quality, such as re_data, great expectations, soda, etc. Tests for checking the number of records, anomalies, and other data observation metrics can be set to monitor the transformations.
- Use Census logs for detecting deletions in the source, duplicates, and weird behaviors. It is a powerful feature that gives insights into the full data pipeline, not only for Reverse ETL.
- Have some independent syncs in Census that tend to update a small set of data, such as users created today, or events in the last 2 hours. Then you will also gain visibility of how your streaming process is performing. Has it really created all the records it should for today? Census logs will show rejections if they did not find the record and you can complete that through a batch sync with Census.
A closing note
Data quality is a result of building healthy data flows, and healthy data flows are not only correct single intra-tool implementations but also a full harmonious integration of implementations. Reverse ETL closes the cycle of a full data flow and usually, when designed correctly, can show you the raw balance of different dimensions of data quality. Use Reverse ETL (we fully recommend Census here) for measuring your data quality and improving the data flow accordingly. Additionally, iterations work better than a waterfall technique for data. While still keeping the big picture in mind, iterate through different implementations until the data flow is behaving as it should.