
Principle-driven development
How we build a team, completely rebuild our core product and ship it to millions every day.
We are a newly formed team, tasked with rebuilding our core product – our document viewer – completely from scratch. General wisdom says that this is a challenge that should be approached cautiously, as the risk of failure is high. How do you ensure team members agree on a direction and create a modern and durable solution while mitigating risks?
We take a holistic view of our entire process, start from six high-level core principles and apply them to all we do. This foundation for our process and code gives us focus and direction for our work, directing our overall architecture, our development process and our roadmap. It is what eventually allows us to build and ship an improved product to millions of users every day. This is the story of how we are building our Reader3.
Who we are
At issuu, we are in the business of distributing documents from our many publishers to be enjoyed and shared by millions of users. There are several ways this takes place. As a publisher, you can distribute your documents on issuu.com, embed them on your own website and promote them through social media. Publishers can also read their own documents as they are being processed for final distribution (which generally takes a little while). In this post we will focus on the consumption part: How do we make sure that users can view documents at scale?
We must listen to each other
We Raptors are the delivery team responsible for the reading experience; users reading documents on issuu.com are our primary customers. We work in true full-stack fashion, and have control over (almost) all aspects of our product and its associated processes. We are a newly formed group consisting of nine people sitting together in the same office: a product manager, a designer, a tester and six software engineers, one of whom is also our team lead.
Our individual pet peeves, personal experiences and favorite annoyances feed into our collective core principles. Our guiding lights are as follows:
- We must listen to each other.
- You should not be the only person knowing this.
- We should give users the best possible experience.
- There should be no surprises.
- We should never be afraid of committing.
- Any feedback loop should be as short as possible.
Clearly, the first principle is the most important and what makes it possible for us to function extremely well as a team. But if any of the others are not met, we are not doing a good enough job and we must rectify it as soon as possible. Below I will show some direct consequences of these extremely important values and how they influence the decisions we make. To begin with, here is how we work on a day-to-day basis.
You should not be the only person knowing this
We loosely follow the scrum methodology, with brief morning stand-ups where the scrum master duty rotates between us all. We work in (generally) one-week sprints scheduled at longer planning meetings. Most of our work is on well-defined user stories with demoable results and their associated feature tests. We also have a burning lane for fixing any urgent and critical bugs (very rarely is anything here), and a quality lane for larger quality improvements we would like to do (such as larger refactorings or build tool improvements).
Us Raptors invest a lot in infrastructure, partly to reduce feedback loops but mostly to remove surprises and improve trust in our code. None of us has any interest in panicky repairing something that broke in production, so almost all of our code is pair-programmed (or at least peer-reviewed). We enjoy working together, believe in investing in high quality and think that we are better collectively. Hence all team members participate in designing both the user experience, the architecture and feature set for each target platform.
What we do
At issuu we are dealing with more than 27 million unique documents, shown to 100 million unique users every month. Every day our readers consume 100 million individual document pages, averaging around 1,000 pages per second. In addition, our readers use all kinds of devices for reading — everything from feature phones in Nigeria to the odd SmartTV in South Korea. Of course, we have to support the most common browsers as well.
We want our users to have the best possible reading experience no matter what their preferred platform is, whether they are reading on issuu.com or on some external site that contains an issuu embed. Historically, this has spurred us to create a number of reader implementations, each suited for a specific use case:
- The Flash Reader: This is presented to all browsers with Flash support. It’s our reader with the best user interface and the most features.
- The HTML5 Reader: This is our first stab at serving documents to mobile devices. It’s also given to any browser without Flash support.
- The Preview Reader: A special reader developed to make a document which is currently processing available for viewing by the publisher who uploaded it.
Each of these readers have their own shortcomings. The Flash implementation suffers from the fact that Flash is dying — fast. It is clearly not the path to the future. The HTML5 reader was developed quickly and specifically for mobile devices (where Flash is not available), so consequently it has a lot of assumptions about the devices for which it was designed for. Finally, the Preview Reader is very specialized to support showing the files as they are being processed. None of the implementations has a modern, extensible platform; their code is hard to maintain and they are not suitable for new features we seek to support.
This much is clear: We need a new Reader. It needs to be truly multiplatform and vastly superior to the old HTML5 reader that is not at all a great experience. We also want it to replace the Preview Reader, and (most importantly of all) it should replace the Flash implementation simply because the new reader offer a better experience. So despite the risks, we are working on making Reader3 a full replacement for all implementations.
(It’s called Reader3 is because we are working on the third full iteration of the core product. The Flash implementation is named Reader2 internally.)
How we do it
Clearly some of the fundamental challenges in systems design are present: scale in users and a very large variety in target platforms. Reader3 has to work great no matter its deployment configuration — either on issuu.com, as an embed on third-party sites or even inside a tweet. It is also obvious that Reader3 cannot be a static product. It must be able to evolve to fit new target platforms and support new features. Oh, and we cannot annoy current users while we are building a replacement reader. The shift must be continuous. So rebuilding a plane in midair it is.
We should give users the best possible experience: Feature set & road map
Old reader implementations live in the wild, and they have a relatively large number of features. Users rely on them to read documents all the time.
Simultaneously, the number of target platforms greatly exceeds what we can hope to test ourselves. We want to avoid big-bang releases and reduce development risk to avoid surprises. So we roll Reader3 out when it is ready to replace an old implementation in a specific deployment scenario. This lets us deploy the most critical code early, as each scenario has different feature set requirements but core functionality is shared across all scenarios. We can thus prove that our approach works, create trust in our code and find and resolve platform or browser bugs before launching to all users.
We decide in what scenarios to replace old readers using use a very simple strategy that doctors also apply when treating patients:
- Avoid making things worse overall.
- Try to make improvements.
By this we mean that our users should get as good an experience with Reader3 as the old implementation that we are replacing. Replacing implementations one scenario at a time, we are able to replace old implementations with ever more features. When doing so, we do not force ourselves into feature parity; we try to remove conceptual debt from old implementations, which means sometimes not including a specific feature or completely changing it.
One example of a deployment scenario is a small document reader embedded on a third-party website, which the user visits using a browser without Flash. This was our first target for replacement, because the old embedded reader in this specific situation was the least featureful. It was simply a link to the publication on issuu.com, showing the cover image of the embedded publication. So we started by building the features of Reader3 necessary to replace that implementation, and initially gave it only to users running Google Chrome. This allowed us to ensure functionality end-to-end, and forced us to focus our effort on building a stable core product with a limited feature set.
We have since moved on to replace the old HTML5 implementation with Reader3 on all third-party sites. That is, Reader3 is served in all issuu embeds to all browsers without Flash support.
Our current goal is to eliminate the old HTML5 implementation completely, which requires us to implement all remaining features for reading documents on issuu.com. This will take us a long way toward replacing the Flash Reader, moving us closer to our goal of only having to maintain a single reader implementation.
There should be no surprises: Technical strategy
Our development principles are quite straightforward:
- Make it simpler if you can.
- Avoid magic if at all possible.
This means that we stick to tried-and-tested, standard Unix tools. We coordinate and instrument our processes with make. Where it makes sense, we build simple tools in Python that improve our tool chain and reduce dependencies. We also avoid magical dependencies that does a lot of behind-the-scenes work, instead favoring clarity and explicitness (at the cost of some additional boilerplate code).
Since Reader3 lives on the web and has to be completely multiplatform, we have to implement it in JavaScript. A lot has happened in the last couple of years in the language, and we want to take advantage of the newest features. So we write ES6/ES2015 Javascript and use Babel to compile it to the ES5 standard that browsers generally accept. We use React and Redux to structure our code; we really like the architecture it leads us into. A large fraction of the implementation consist of pure functions, making our code simple to test and reason about.
We should never be afraid of committing: Continuous Delivery
Any active software development process can be reduced to very few subprocesses. Generally as a software engineer, you are interested in either developing, testing or deploying your code. Each of these processes has some prerequisites, such as building the code or having dependencies installed, but the goal and the resulting workflow for each is unique. The ergonomics of the development process must be good, you must be able to trust that your tests are able to catch errors and deployment should be repeatable and trustworthy.
As a direct consequence of our guiding principles, we set some very simple (but hard to achieve) goals for our develop/test/deploy process. Our primary aims are to avoid surprises, remove fear of committing and keep feedback loops short. That means the following:
- Code on master should be in production.
- Don’t be scared of pushing to master (also in the afternoon).
- See consequence of change as soon as possible.
- Test and deploy should be as fast as possible.
We heavily rely on Continuous Delivery to meet these goals, thinking of it as composed of two separate phases that automates the testing and deployment phases.
Given a specific code commit, Continuous Integration is to make sure that the code works as expected; the goal is to build and test the code running in a test environment (which should model the real production environment very closely). This generates a verified and tested release, which is ready to be deployed.
Continuous Deployment is to deploy the tested release to a target environment. This can be done more or less aggressively, but generally the release is deployed to some fraction of users where it is tested in the wild. If all goes well, the release is automatically promoted and given to all users.
Our makefile contains all process definitions: how we install all dependencies, how to start our development environment, how tests are executed and how we deploy reader3 to our target environments. This gives us very simple reproducibility and extremely limited amount of configuration in our continuous delivery system (currently Jenkins). The goal of course is that all configuration should live in code, but we’re not quite there yet.
We automatically build all changes to our master branch and run our regression-test suite on them. If all tests succeed, a new versioned release is created and immediately pushed to production. The time from a change is pushed and until a new release is live is around 5 minutes, everything included.
Development Our repository includes an automatically installed precommit hook that ensures we cannot accidentally commit trivial errors and have them break our build. It runs linting and unit tests and only lets us commit if it finds no errors. When working on a new feature, we sometimes use feature flags to deploy the changes internally at issuu for review, or to allow us to split big changes across several commits. As browsers have different capabilities, we use a couple of polyfills to take advantage of new browser APIs and language features in older browsers. To be able to develop Reader3 for the different deployment configurations, we maintain simulated deployment configurations for each scenario. As it can be embedded on third-party websites, we use a proxy server to test bug fixes and changes to our implementation against specific sites. This is necessary because all sorts of madness can happen in the browser in such a deployment scenario. We essentially cannot guarantee how Reader3 will look on third-party sites.
Testing We build our code to be testable on a unit-test level. This means a lot of pure functions, manually injected dependencies and use of no global variables. Following those principles allows us to implement unit tests with very few mocks. We do not have full code coverage yet, but are continually working in that direction. To that end, we often use test-driven development when implementing new functionality.
To make sure that we meet our business requirements and avoid accidentally breaking some features, we maintain an extensive test suite that implement feature tests for all our reader features. The test suite lets us easily test the implementation in a variety of browsers (those that can be reasonably instrumented by Selenium using WebDriver). Our feature tests are a prime generator of code trust, and nothing hurts trust in tests more than flapping tests. So they have to be written with caution to ensure reliability. Consequently, we have invested in building tools that remove any external dependencies when running our feature test suite, making them run completely offline. Importantly, the feature test suite runs against deployed configurations of Reader3, making certain that we have not broken the integrated product. So when our tests pass, we are pretty comfortable that our changes are not breaking anything.
Deployment We do not want to be scared of committing, or afraid of pushing our changes to production. If a corner of Reader3 needs to be fixed during a Friday afternoon, we do not want to be hindered in pushing out that change. This is the reason we have focused on pushing all changes to production immediately; we believe that the only way to be comfortable doing something is to do it very often. So we deploy a new version of Reader3 to production on every successful change to our master branch, around five times a day. If a particular release breaks anything, we can always roll back to a version which is known to be good. Our versioned releases and continuous deployment procedures makes this trivial.
To make sure that a particular release worked as expected, we initially did a gradual rollout to around 10% of our users, followed 30 minutes later by an automatic rollout to all users. However, after some time the quality of our test suite and our general code confidence meant that this turned into an annoyance, never catching errors and just delaying our deploy feedback loop. So now we disabled this feature, and simply deploy releases to all users when the tests pass.
Of course, we want to deliver reader3 to our users as quickly as possible. So we pack our Javascript files together in a single minified bundle (and keep a sourcemap for debugging purposes). Reader3 may be embedded on third-party websites, meaning that it must be available at all times and fast to fetch for users all over the world. So we serve our resources through a CDN, backed by Amazon S3.
Any feedback loop should be as short as possible: Measure, rinse & repeat
We strongly believe that the only way to figure out if we’re doing a good job is to let our users tell us through their actions. Only by learning through data can we improve the user experience and make Reader3 a better product. So we measure.
Nobody would ever deploy a back-end service used by millions and not invest in measuring, monitoring and tracking user behavior, performance and errors. Yet when the code runs on the front end, this is not unheard of. If we are to trust our code and get short feedback loops, this is simply not acceptable. So we measure.
Performance tracking We invest a lot in tracking a myriad of important user metrics that help us make sure that Reader3 is performing well on all supported platforms. Our key metrics are collected on a couple of dashboards and always visible on our monitoring screens in the office. With Reader3 being a Javascript application with so many target devices and deployed configurations, we need to rely on user tracking to make sure that our code is stable and fast. Hence, every instance of Reader3 will send anonymized observations back to issuu servers. This allows us to monitor metrics that help us improve the product, such as the following:
- How much time does it take for the first page in a magazine to be visible?
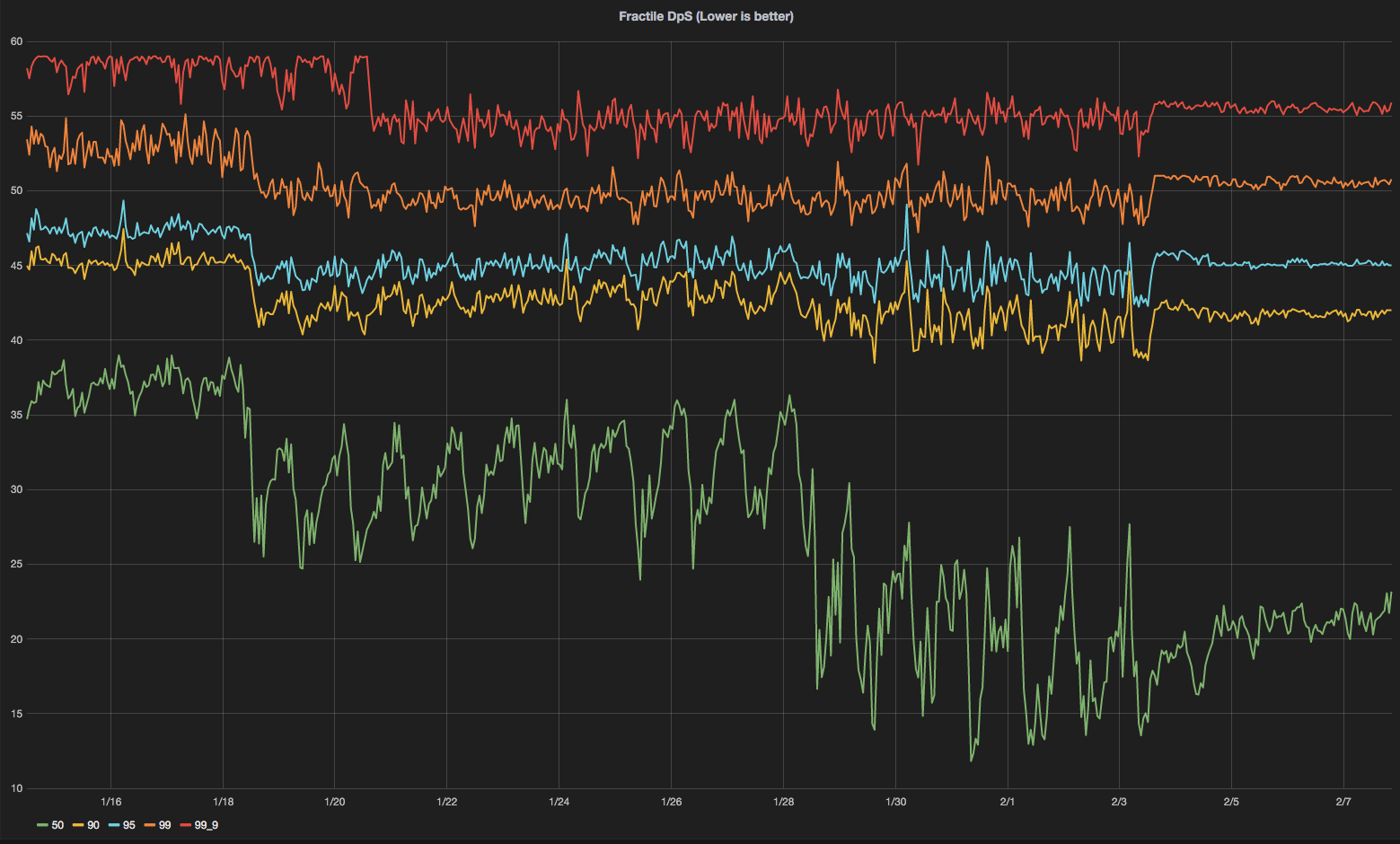
- How fluent are our animations? Do we drop many frames when rendering? Focusing on performance had an impact on the number of dropped frames most users saw, as proven by the following graph. Each of the lines show the number of dropped frames per second for different user fractiles (i.e. the median user sees around 20 frame drops per second, whereas around 45 frames are dropped at the 90th fractile).
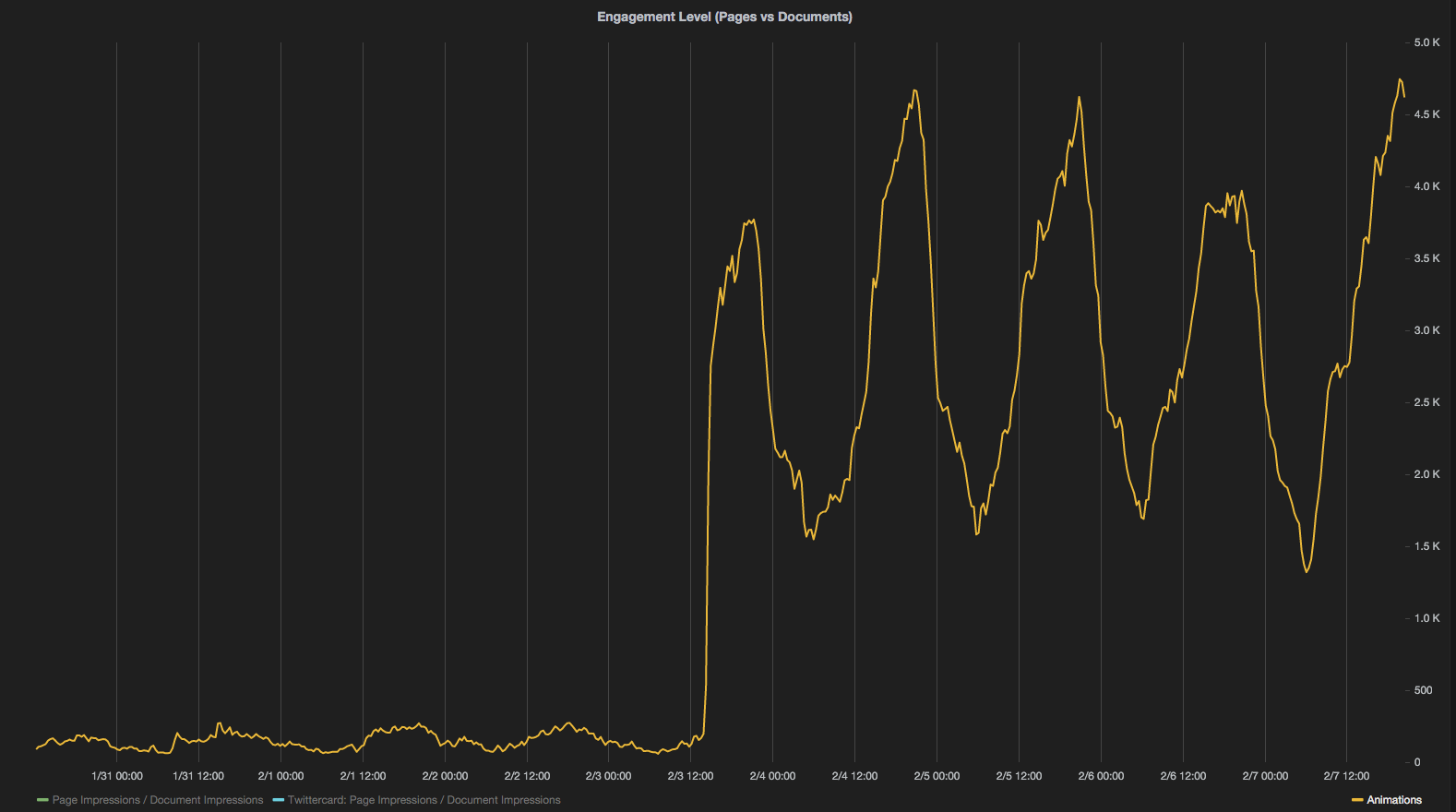
- How often do users interact with the reader and what features do they use? Not surprisingly, it turns out that our users interact much more with Reader3 if we make its functionality obvious. For example, this graph shows a ten-fold increase in the number of interactions performed after we decided to show navigation arrows to all users (from around 400 to around 4000 interactions per minute).
Our metrics give us a tool to evaluate our changes. If we are working on making Reader3 faster, we hope to see the animation fluency improve on user devices. Hopefully we can measure increased user interaction when changing or modifying its features. Perhaps needless to say, the data we gather already have shown its value in the scenarios I just outlined, among many others.
Error tracking Did I mention how many different target platforms we target with Reader3 and the number of deployment configurations? The sheer variety makes it completely infeasible to test on all possible devices. So instead, we test on the most common devices and browsers, and rely on error logging from the clients to let us know if we’ve introduced bugs on less-common platforms. We use the Sentry logging server to receive the logs and monitor them in real time. This gives us an extremely short feedback loop in detecting and fixing bugs. If something slips through our pair programming and tests, we know about it and can deploy a fix within minutes from deploying to production.
Stick to the principles
Working on Reader3, we are touching new ground with each feature we implement because it is a completely new product. Still, procedural or technical debt can quickly accumulate, so we continually look back at our code and process and try to iron out any kinks we may have introduced. We use our core principles as a guiding light.
- We must listen to each other.
- You should not be the only person knowing this.
- We should give users the best possible experience.
- There should be no surprises.
- We should never be afraid of committing.
- Any feedback loop should be as short as possible.
In all we do, we try to further our focus on those values. Any discussions are very constructive because we can always evaluate our solutions against our guiding principles and see the results through data. It gives great satisfaction to work like this. The whole team enjoys working together, our code quality is excellent and we agree on the overall goal and direction.
Stick to your principles. Apply them. Focus.