
Abandoning the mothership
The time had come to pour into our front-end code the same poison we had given our back-end systems.
Part 2 of “Toward a maintainable front-end” series. Part 1 is here.
For many years, issuu’s engineering group was organized around component teams. Our late great Team Monster handled the front-end code and the rest of the teams provided APIs and back-end infrastructure.
As we scaled the engineering organization, this classical split became counterproductive. A lot of cross team coordination was required for releases. Business logic and remappings were spread across multiple layers of the application. Dependencies and ownership of features were unclear. Finally, the Monsters had way too much on their plate!
So in 2013, several of our teams transitioned from component teams to customer-centric, cross-component feature teams. One focused on the end-to-end reading experience, another team handled all publisher-related features and so on. Next was taking ownership of the entire code stack, from database to front end. Our back-end system quickly transitioned into smaller microservices written in technologies the team deemed best (OCaml, Erlang, Python, node.js, MySQL, Postgres, Redis, AMQP).
Until recently, though, the front-end code running issuu.com was still one big, monolithic codebase. It had turned into such an unmanageable beast that we were all fighting with each other to get features out to users. We identified several blockers:
- With one big pile of code, team ownership and dependencies were unclear;
- we stepped on other people’s toes all the time;
- and as a result the rate of feature deployment decreased. (Oh yes, big-bang releases!)
Besides, we had a major technology lockdown due to a very customized build system. This alone was around 3.000 lines of code, including a home-built Browserify and a lot of magical grunt tasks. As nobody dared to touch that part of the system, we were locked to our own require system, ES5 and Ruby SASS. Also the size of the codebase made builds painfully slow.
It was time to pour into our front-end code the same poison we gave our back-end systems, splitting it all apart into maintainable chunks. Our vision was to make each feature team own, build and deploy its front-end code autonomously — and to make things that ought to be trivial actually trivial!
To the lifeboats!
We started by dividing the front-end codebase into four chunks:
- shared serving infrastructure;
- pages;
- widgets;
- and UI components.
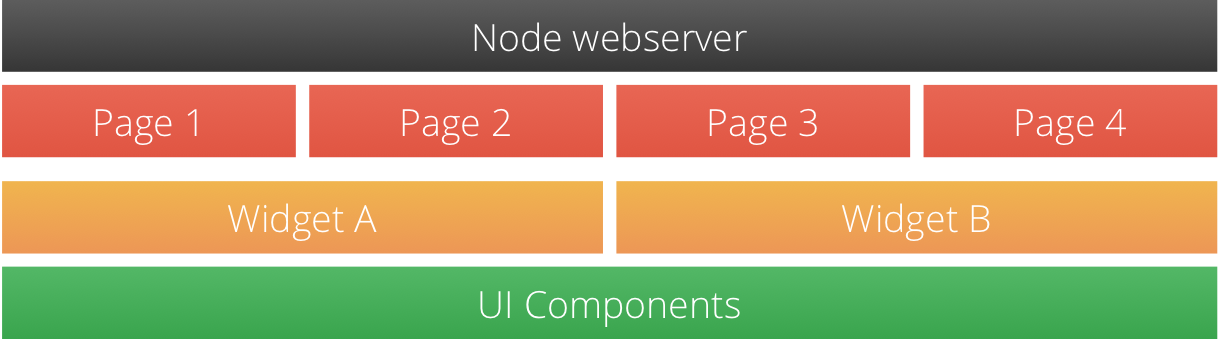
The shared serving infrastructure is a thin horizontal node.js application responsible for routing and serving pages. It holds the configuration for which version of a page to be served.
A feature team delivers products consisting of the following:
- pages (node.js handlers, templates and assets like compiled JavaScript/CSS);
- and some widgets (shared functionality used on multiple pages, like a message hub, streams or drag-and-drop functionality to initiate a publication upload).
Our UI component package provides high-level building blocks and styling for the site. It is our shared horizontal toolkit for keeping a consistent look and not reinventing buttons, form elements, modals and colors for each page and widget.
To handle internal code dependencies, we decided to use the same tool we use for all other dependencies in JavaScript: npm. So we set up a private npm repository using the open-source Sinopia tool. When pushing code on master for one of our front-end repositories, our CI server will test and publish a new version of the package to Sinopia.
To release a change to a page, you simply bump the product version in the shared webserver package. The package.json for our webserver looks like this:
{
"dependencies": {
"issuu-productA": "1.0.2",
"issuu-productB": "2.0.292",
"issuu-productC": "1.0.x"
...
}
}
To follow the principle of least astonishment, most of our top-level packages are locked to a specific version of a page, but some packages like Marketing pages will always take the newest version.
How did we migrate to this? After the initial serving infrastructure was ready, we made it up to the feature teams to take ownership of the old mothership codebase and turn it into a product/widget in the new world. Of course, the mothership still holds tight to some old products we never touch and that no team really owns. In the end, it is all about ownership.
After a few months, the old monolithic codebase is split into 45 packages. Oh, 46 now!
A new hope
Instead of the old, frustrating technology lockdown, over the last six months a lot our feature teams have been innovating on the tools they have for building products. Most of the teams use the following:
- Makefiles for orchestrating everything (why reinvent the wheel?);
- Webpack for building assets;
- Babel for allowing us to write slick ES6 code that transpiles to ES5;
- a move to React and Redux;
- strict linting using ESLint;
- and more as we go. Nothing stops a team from trying out TypeScript, CSS Modules, Elm, etc.
We are now able to work on isolated, vertical features without worrying about stepping on toes. Deployment time went from 30 minutes to just a few minutes, as we are rebuilding only what have changed and not the entire codebase. We went from a few weekly deploys to multiple times daily — continuous delivery for the win!
The one constraint for a product is that it can be served by node. Heck, we are already talking about breaking the horizontal node server into smaller servers and letting the top-level routing logic reside in a proxy configuration. Ultimate autonomy to the team.
A note on sharing code, and lessons learned
We want to make fast iterations on products and sustain team autonomy. Our new system is optimized for changes in issuu’s vertical products, not for making horizontal changes easier. It highlights clearly that we still have a lot of horizontal dependencies.
In our old mothership repository, it is very easy to make a horizontal change and share a lot of code between products. One thing the code split has highlighted is that developers intuitively love to share code. Instead of copying and pasting small pieces, we would rather generalize it into shared components. This comes at a high cost: You now have yet another dependency, and dependencies slow you down. You lose autonomy and make simple things complex.
On the scale of a single product or feature, team code reuse and the principle of DRY still make sense. But one should be careful about sharing code between products as shared dependencies are cumbersome. Of course, you never want to duplicate business logic, but I would much rather duplicate simple components than share them between verticals.
Still, redundancy sucks, right? I’m going to end with a quote from the excellent post by Yossi Kreinin:
Redundancy always means duplicated efforts, and sometimes interoperability problems. But dependencies are worse. The only reasonable thing to depend on is a full-fledged, real module, not an amorphous bunch of code. You can usually look at a problem and guess quite well if its solution has good chances to become a real module, with a real owner, with a stable interface making all its users happy enough. If these chances are low, pick redundancy. And estimate those chances conservatively, too. Redundancy is bad, but dependencies can actually paralyze you. I say kill dependencies first.